LeetCode 探险模式
数据结构与算法
数组 Ⅱ
Q3. 找到所有数组中消失的数字
给你一个含
n个整数的数组nums,其中nums[i]在区间[1, n]内。请你找出所有在[1, n]范围内但没有出现在nums中的数字,并以数组的形式返回结果。示例 1:
2
输出:[5,6]示例 2:
2
输出:[2]提示:
n == nums.length1 <= n <= 1051 <= nums[i] <= n进阶: 你能在不使用额外空间且时间复杂度为
O(n)的情况下解决这个问题吗? 你可以假定返回的数组不算在额外空间内。
解法 1
算法与数据结构
利用哈希表,遍历一遍数组,记录所有数字出现的次数。最后遍历哈希表,找到未出现的数字即为结果。
参考代码
1 | class Solution { |
注:operator[] 在 key 不存在时会默认插入,如果使用
if (mp[i] == 0) 判断,若 i 不存在于
mp,会自动插入
{i: 0}。虽然不影响正确性,但是会导致第二轮循环中
mp 不断膨胀。
复杂度分析
- 时间复杂度:
,循环遍历的复杂度为 ,哈希表插入与查询均为 ; - 空间复杂度:
,哈希表最多存储 个键值对;
解法 2
算法与数据结构
既然数组内元素的范围是
参考代码
1 | class Solution { |
复杂度分析
- 时间复杂度:
,循环遍历的复杂度为 ,哈希表插入与查询均为 ; - 空间复杂度:
;
栈
Q3. 程序的独占时间
有一个 单线程 CPU 正在运行一个含有
n道函数的程序。每道函数都有一个位于0和n-1之间的唯一标识符。函数调用 存储在一个调用栈上 :当一个函数调用开始时,它的标识符将会推入栈中。而当一个函数调用结束时,它的标识符将会从栈中弹出。标识符位于栈顶的函数是 当前正在执行的函数 。每当一个函数开始或者结束时,将会记录一条日志,包括函数标识符、是开始还是结束、以及相应的时间戳。
给你一个由日志组成的列表
logs,其中logs[i]表示第i条日志消息,该消息是一个按"{function_id}:{"start" | "end"}:{timestamp}"进行格式化的字符串。例如,"0:start:3"意味着标识符为0的函数调用在时间戳3的 起始开始执行 ;而"1:end:2"意味着标识符为1的函数调用在时间戳2的 末尾结束执行。注意,函数可以 调用多次,可能存在递归调用 。函数的 独占时间 定义是在这个函数在程序所有函数调用中执行时间的总和,调用其他函数花费的时间不算该函数的独占时间。例如,如果一个函数被调用两次,一次调用执行
2单位时间,另一次调用执行1单位时间,那么该函数的 独占时间 为2 + 1 = 3。以数组形式返回每个函数的 独占时间 ,其中第
i个下标对应的值表示标识符i的函数的独占时间。示例 1:

2
3
4
5
6
7
输出:[3,4]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,于时间戳 1 的末尾结束执行。
函数 1 在时间戳 2 的起始开始执行,执行 4 个单位时间,于时间戳 5 的末尾结束执行。
函数 0 在时间戳 6 的开始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 1 = 3 个单位时间,函数 1 总共执行 4 个单位时间。示例 2:
2
3
4
5
6
7
8
9
输出:[8]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,并递归调用它自身。
函数 0(递归调用)在时间戳 2 的起始开始执行,执行 4 个单位时间。
函数 0(初始调用)恢复执行,并立刻再次调用它自身。
函数 0(第二次递归调用)在时间戳 6 的起始开始执行,执行 1 个单位时间。
函数 0(初始调用)在时间戳 7 的起始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 4 + 1 + 1 = 8 个单位时间。示例 3:
2
3
4
5
6
7
8
9
输出:[7,1]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,并递归调用它自身。
函数 0(递归调用)在时间戳 2 的起始开始执行,执行 4 个单位时间。
函数 0(初始调用)恢复执行,并立刻调用函数 1 。
函数 1在时间戳 6 的起始开始执行,执行 1 个单位时间,于时间戳 6 的末尾结束执行。
函数 0(初始调用)在时间戳 7 的起始恢复执行,执行 1 个单位时间,于时间戳 7 的末尾结束执行。
所以函数 0 总共执行 2 + 4 + 1 = 7 个单位时间,函数 1 总共执行 1 个单位时间。提示:
1 <= n <= 1002 <= logs.length <= 5000 <= function_id < n0 <= timestamp <= 109- 两个开始事件不会在同一时间戳发生
- 两个结束事件不会在同一时间戳发生
- 每道函数都有一个对应
"start"日志的"end"日志

算法与数据结构
用栈操作模拟函数调用过程。
调用一个函数时,如果已经有函数在运行,则停止当前运行的函数并计算其目前的执行时间,然后将调用函数入栈;调用结束后,弹出栈并计算执行时间,继续执行栈顶被暂停的函数。
参考代码
1 | class Solution { |
复杂度分析
- 时间复杂度:
, 为日志数量,对应 次入栈和出栈; - 空间复杂度:
,最坏情况下 条日志全部入栈才依次出栈;
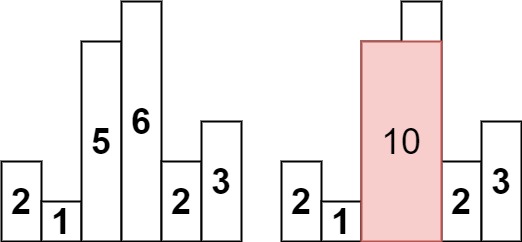
Q3. 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
2
3
输出:10
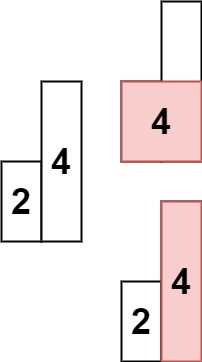
解释:最大的矩形为图中红色区域,面积为 10示例 2:
2
输出: 4提示:
1 <= heights.length <=1050 <= heights[i] <= 104
算法与数据结构
维护一个单调递增栈(存下标),遍历每根柱子:
- 当前柱子高度 ≥ 栈顶 → 直接入栈
- 当前柱子高度 < 栈顶 → 说明栈顶柱子的 "右边界" 已确定,弹出并计算面积
弹出栈顶 top 时:
- 高度 =
heights[top] - 宽度 = 当前下标
i到新栈顶之间的距离(即i - st.top() - 1)
并且在末尾追加一个高度为
参考代码
1 | class Solution { |
复杂度分析
- 时间复杂度:
,每个元素最多入栈出栈各一次; - 空间复杂度:
,栈的最大深度;
堆
Q2. 查找和最小的 K 对数字
给定两个以 非递减顺序排列 的整数数组
nums1和nums2, 以及一个整数k。定义一对值
(u,v),其中第一个元素来自nums1,第二个元素来自nums2。请找到和最小的
k个数对(u1,v1),(u2,v2)...(uk,vk)。示例 1:
2
3
4
输出: [[1,2],[1,4],[1,6]]
解释: 返回序列中的前 3 对数:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]示例 2:
2
3
4
输出: [[1,1],[1,1]]
解释: 返回序列中的前 2 对数:
[1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]提示:
1 <= nums1.length, nums2.length <= 105-109 <= nums1[i], nums2[i] <= 109nums1和nums2均为 升序排列1 <= k <= 104k <= nums1.length * nums2.length
算法与数据结构
由于两个数组是非递减排序的,因此结果一定出现在下表的左上角部分
nums1[0] |
nums1[1] |
nums1[2] |
nums1[3] |
nums1[4] |
|
|---|---|---|---|---|---|
nums2[0] |
{0,0} |
{1,0} |
{2,0} |
{3,0} |
{4,0} |
nums2[1] |
{0,1} |
{1,1} |
{2,1} |
{3,1} |
{4,1} |
nums2[2] |
{0,2} |
{1,2} |
{2,2} |
{3,2} |
{4,2} |
nums2[3] |
{0,3} |
{1,3} |
{2,3} |
{3,3} |
{4,3} |
构建一个小根堆,存储表中元素,首先初始状态存储第一列的 {0,0},然后将 {0,0}
写入结果,再将第一行元素依次加入小根堆,在 {0,1} 和
{1,0} 中选更小的写入结果,以此进行……
小根堆维护的是每一行中还没有被取出的元素。
注:保证没有漏掉全局最小——假如 {i,j}
没在堆里,那么说明还有一个更靠左的点 {i,t}
没有被取出,就轮不到 {i,j} 入堆,其中
参考代码
1 | class Solution { |
复杂度分析
时间复杂度:
,每次入堆后,调整位置的时间复杂度为 ,入堆 次,出堆 次; 空间复杂度:
,堆中最多保存 个元素;