高速缓存
计算机程序运行时遵循局部性原理:
- 时间局部性:程序中的某条指令被执行,不久后该条指令可能再次被执行;某数据被访问,不久后该数据可能再次被访问(保留一段时间,等到之后被访问)
- 指令循环执行
- 局部变量集中存储,被频繁访问
- 空间局部性:程序访问了某个存储单元,它附近的存储单元也可能被访问(将邻近单元内容调入,等待之后被访问)
- 指令顺序执行
- 数组
引入高速缓存
典型的存储器层次结构如下图
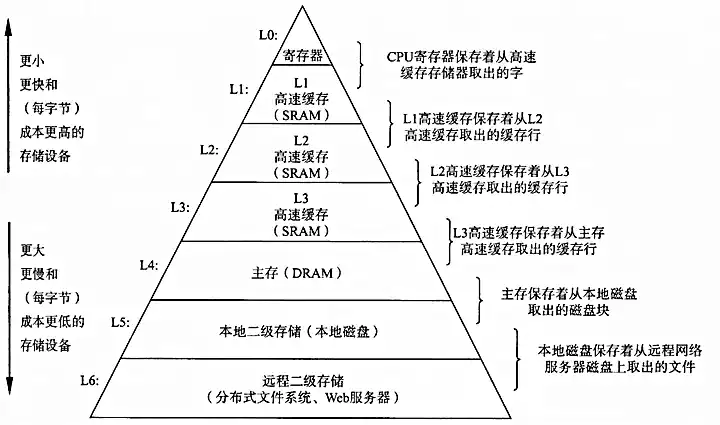
CPU 设计的目的是实现高速计算,存储器设计的目的是实现大容量存储,两种器件需要分离。为了获得存取时间和存储容量的折中(tradeoff),弥补 CPU 与内存的性能差异,把 CPU 性能的提升利用起来,在 CPU 内部引入了高速缓存。从 CPU Cache 被加入到现有的 CPU 开始,内存中的指令、数据会被加载到 L1-L3 中,而不是 CPU 问内存去拿,其中 L1-L3 指由 SRAM(static RAM)组成的物理芯片。
运行程序的主要事件花在了将对应的数据从内存中读取出来,加载到 CPU
Cache 中,读取的单位称作 Cache Line(缓存块),大小通常是
高速缓存采用纯硬件设计,原因包括:(参考 AI)
高速缓存(Cache)是计算机体系结构中的一个重要组成部分,它位于 CPU 和主内存之间,用于减少处理器访问内存所需的时间。高速缓存采用纯硬件设计的主要原因有以下几点:
速度需求:为了匹配 CPU 的高速度,Cache 需要极快的响应时间。纯硬件设计可以提供更低的访问延迟,因为它是通过电路直接实现的,而不需要操作系统的介入。
传输效率:硬件设计可以支持并行处理,这意味着 Cache 可以同时处理多个数据请求,从而提高数据传输的效率;硬件 Cache 能够直接在 CPU 和内存之间进行数据的快速传递,而不需要经过操作系统或其他软件层。这样可以避免软件层的开销,提高数据传输的效率。
预测和预取:硬件 Cache 能够实现复杂的预测算法和预取策略,如旁路预测和指令预取,这些算法可以提前将可能需要的数据加载到 Cache 中,从而进一步提高性能。
一致性:在多处理器系统中,保持内存的一致性是一个复杂的问题。硬件 Cache 通过使用一致性协议(如 MESI 协议)来确保不同 CPU 核心看到的内存视图是一致的。
专用性:硬件设计可以根据 Cache 的特定需求进行优化,如缓存行的设计、关联度、替换策略等,这些优化可以显著提高 Cache 的命中率。
集成性:随着工艺技术的发展,将 Cache 集成到 CPU 芯片内部成为可能,这样可以进一步减少访问延迟,并提高整体的系统性能。
稳定性:硬件设计一旦完成并验证,通常非常稳定,不易受到软件错误的影响。减少了开发人员编写和管理缓存逻辑的需求。这样可以避免由于软件实现的错误而导致的缓存管理问题。
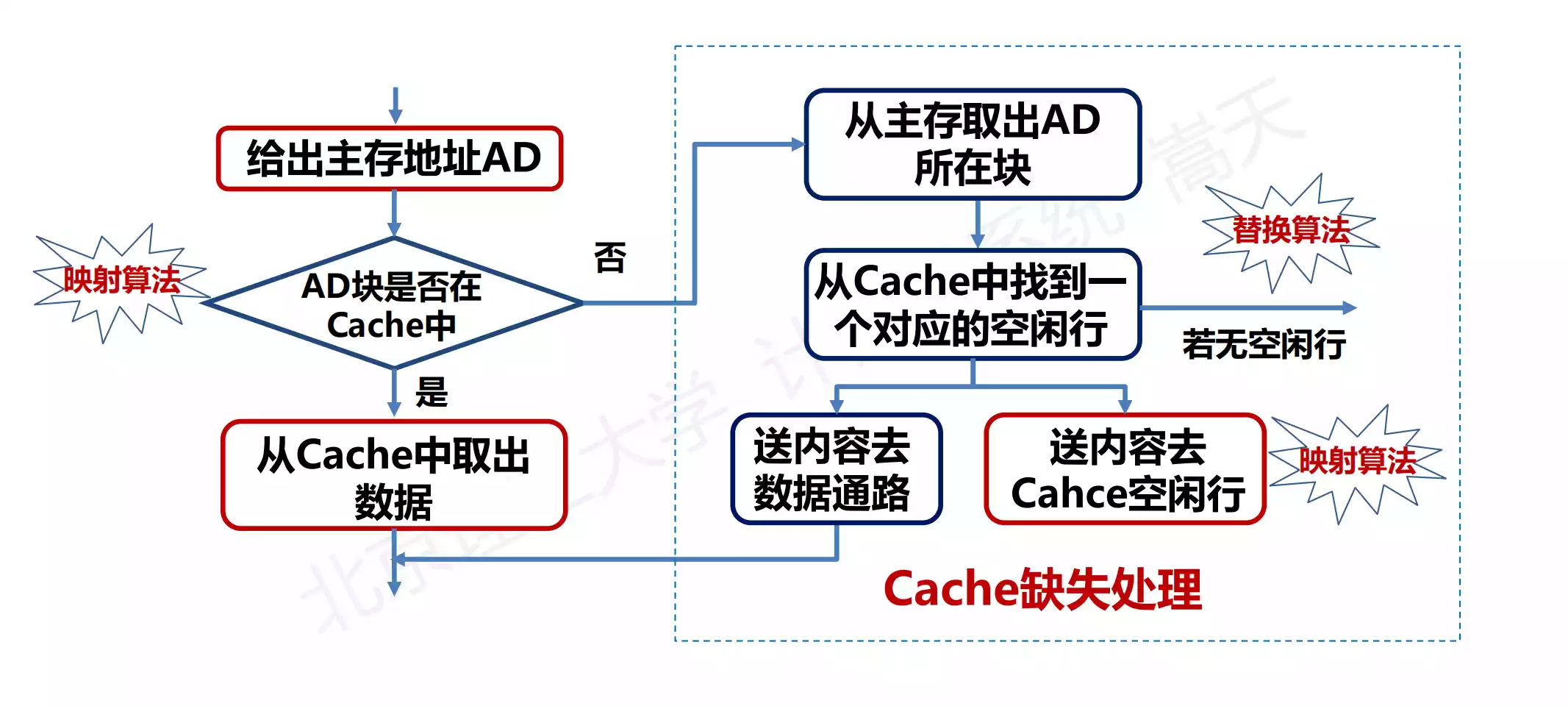
Cache 的工作原理
- 块(Block):Cache 与主存交换数据的大小;
- 行(Line):Cache 中存放一个数据的大小,标记包含一个有效位,表示行内数据是否有效,上电时所有行均无效
现代 CPU 进行数据读取的过程中,无论数据是否已经存储在 Cache 中,CPU 始终会 首先访问 Cache,只有当 CPU 找不到数据时,才会访问内存,并且读取到 Cache 中。
命中率
:CPU 访问单元所在的主存块在 Cache 中的概率 命中时间
:从 Cache 中获得数据的时间 主存访问时间
:从主存获得数据的时间 平均访问时间
Cache 的映射方法
Cache Line 与主存地址的映射。由于 Cache 全硬件执行,CPU 不可见,即不存在 Cache 地址
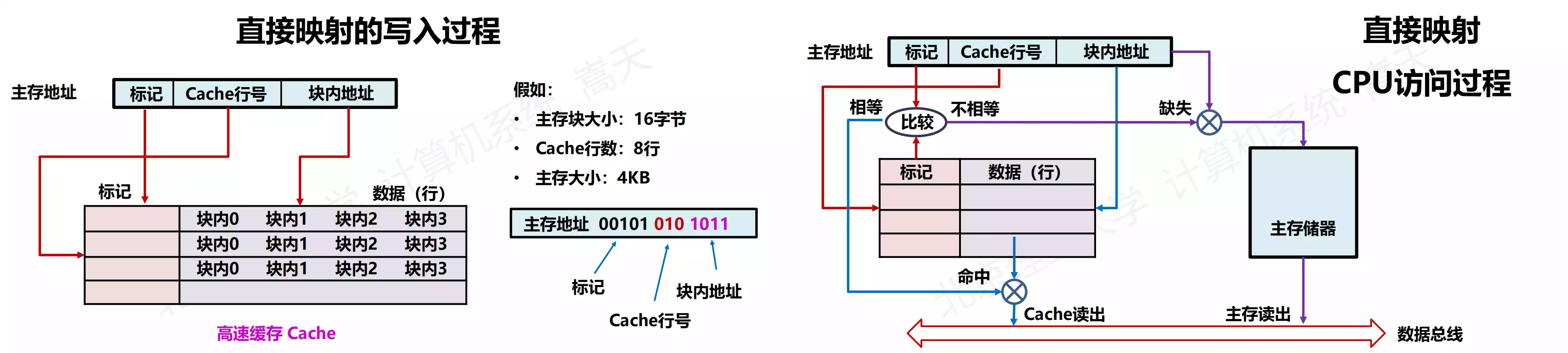
直接映射(Direct)
直接映射(Direct):每个主存块映射到 Cache 的 固定行(模运算);
全相联映射(Full Associate)
全相联映射(Full Associate):每个主存块映射到 Cache 的 任意行;
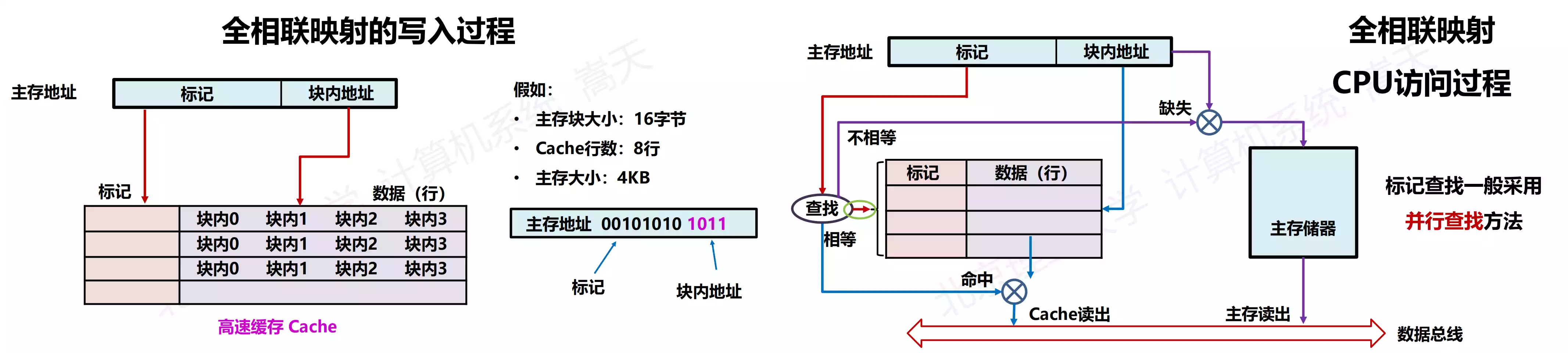
组相联映射(Set Associate)
组相联映射(Set Associate):每个主存块映射到 Cache 固定组的任意行;实现组间直接映射(分组减少并行查找),组内全相联映射。
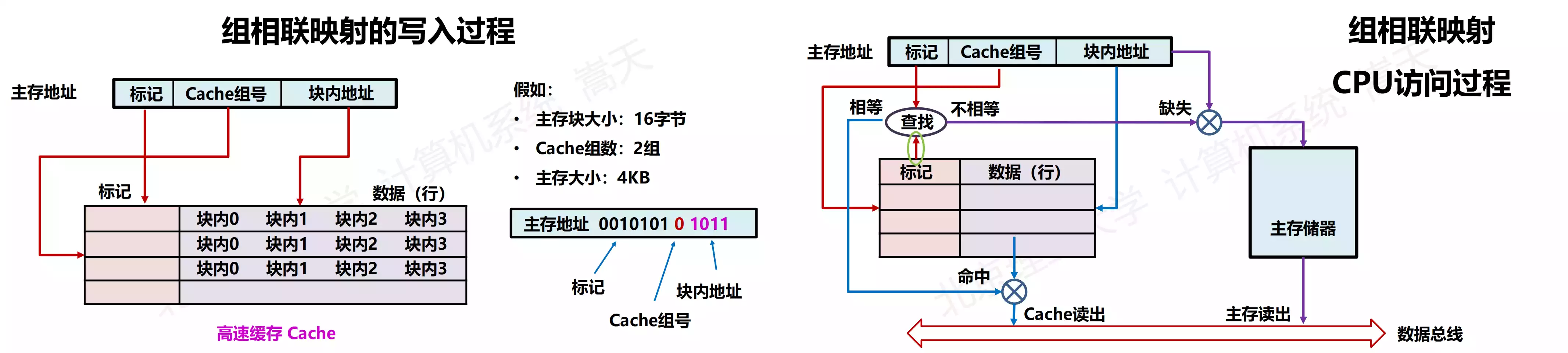
映射方法比较
| 方法 | 优点 | 缺点 |
|---|---|---|
| 直接映射 | 唯一映射、确定性获取,缓存获取快 | 空间利用不充分,命中率低 |
| 全相联映射 | 空间利用充分,命中率高 | 命中判断开销大,缓存获取慢 |
| 组相联映射 | 折中(空间利用充分,组内判断开销可控) |
Cache 的替换算法
FIFO(First In First Out), LRU(Least Recently Used), LFU(Least Frequently Used), Random
Cache 的写入策略
我们现在用的 Intel CPU,通常是多核的,每个核有独立属于自己的 L1、L2 Cache,还有多个核共用的 L3 Cache、主内存。写入 Cache 的性能比写入主内存快,那么应该将数据写入 Cache 还是直接写入主存?如何保证多核 Cache 数据的一致性。
写直达(Write-Through)
graph LR
A [内存数据写入请求] ---> B{缓存命中}
B -- 命中 --> C [数据写入到 Cache]
B -- 未命中 --> D [数据写入到主内存]
C --> D
D --> E [完成]
如果数据在 Cache 中,先写到 Cache 中,再写到主内存中;如果不在 Cache 中,就直接更新主内存。这种策略速度很慢,无论数据是否在 Cache 中,都需要把数据写入主存。
写回(Write-Back)
graph TB
A [内存数据写入请求] --> B{缓存命中}
B -- 命中 --> C [写入数据到 Cache]
B -- 不命中--> D [定位用户缓存的 Cache]
D --> E{Cache 是否标记为“脏”}
E -- 是 --> F [将 Cache 中的数据写回主内存]
F --> G [从主内存读取数据到 Cache]
E -- 否 --> G
G --> C
C --> H [将 Cache 标记为“脏”]
H --> I [完成]
如果要写入的数据在 Cache 中,就只更新 Cache 里面的数据。同时标记 Cache 里的这个 Block 是脏的(Cache 中的数据与主存不一致)如果要写入的数据所对应的 CacheBlock 里,放的是其它内存地址的数据,就要判断 CacheBlock 里面的数据有没有被标记成脏的。如果是脏的话,要先把这个 CacheBlock 里面的数据,写入到主内存里面,然后再把当前要写入的数据写入到 Cache 里,同时把 CacheBlock 标记成脏的。如果 Block 里面的数据没有被标记成脏的,那么我们直接把数据写入到 Cache 里面,然后再把 CacheBlock 标记成脏的。
写回策略要求加载内存数据到 Cache 时,若 Cache Block 有脏标记,需先写回主内存,再加载新数据覆盖 Cache。此策略下,若多次操作都能命中缓存,因选择性写存,多数时间无需读写主内存,性能远超写直达。标记脏数据旨在实现此优化。
多核 Cache 之间的一致性
使用多核 CPU 可以提高 CPU 吞吐率,但是也带来了缓存一致性的问题。多个 CPU 核共享 L3 Cache,它们 L2 Cache 中数据可能不同,导致 缓存一致性问题
- 写传播:在一个 CPU 核心里,我们的 Cache 数据更新,要能够传播到其它对应节点的 Cache Line 中
- 事务的串行化:在一个 CPU 核心里数据的读取和写入,在其它节点看起来顺序是一样的。这类似于多个不同的连接访问数据库时,也必须要保证事务的串行化。
总线嗅探
为了解决多个 CPU 之间的数据传播问题,需要用到 总线嗅探,本质上就是把所有读写请求通过总线广播给所有的 CPU 核心,然后让各个核心去嗅探这些请求,根据本地情况响应。基于总线嗅探机制,最常用的是 MESI 协议。
MESI 协议
MESI 是一种 写失效 协议,只有一个 CPU 核心负责写数据,其它的核心只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,会广播一个“失效”请求告诉其它的 CPU 核心,其它的 CPU 核心自己是否有“失效”版本的 Cache Block,然后也标记成“失效”的。
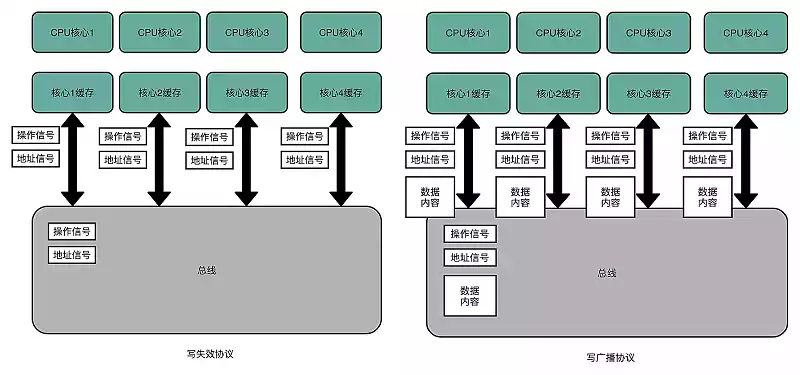
相对于 写失效 协议,还有 写广播 协议,即一个写入请求广播到所有的 CPU 核心,同时更新到各个核心的 Cache,这需要更大的带宽(写失效只需要告知失效的缓存,写广播还需要传输对应的数据)
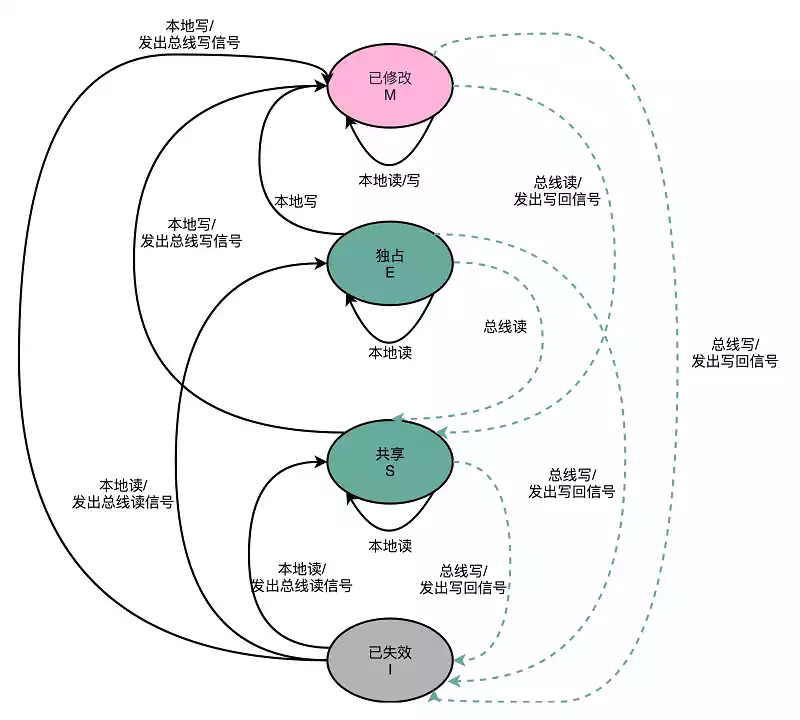
MESI 协议 对应了 Cache Line 的四种状态标记
- Modified:已修改的脏数据,Cache Block 已经更新,但是没有写存;
- Exclusive:独占,对应的 Cache Line 只加载到了当前 CPU 核对应的 Cache 中,其它核并没有加载数据到自己的 Cache 里,此时可以自由地写入数据而不需要告知其它核;
- Shared:共享,在独占状态下,如果收到了来自于总线的读取对应缓存的请求,就会变成共享状态。这时想更新数据,就不能自由修改,而需要向其它 CPU 核心广播一个请求(RFO, Reuquest For Ownership),将其它 CPU 核心的 Cache 变成无效状态,然后更新当前 Cache 中的数据;
- Invalidated:Cache Block 中的数据已失效;
Java 关键字 volatile
的解释
实验过程
实验程序如下:
1 | public class VolatileTest |
程序中定义了一个 volatile 修饰的 int 变量
COUNTER。然后,定义了两个单独的线程,分别为
ChangeListener 和 ChangeMaker
ChangeListener:监听COUNTER,如果发生变化,输出COUNTER的值,直到COUNTER达到; ChangeMaker:每隔COUNTER自增,直到 COUNTER达到
在 main
函数中,分别启动这两个线程,观察程序输出结果:
1 | Incrementing COUNTER to : 1 |
去掉修饰 COUNTER 的
volatile,输出结果:
1 | Incrementing COUNTER to : 1 |
此时让 ChangeListener 在循环中等待
5ms,输出结果:
1 | Incrementing COUNTER to : 1 |
解释
volatile 关键字会
确保我们对变量的读写都同步到主内存里,而不是从 Cache
里面读取。
使用
volatile关键字时,两个线程的输出结果相同;去掉
volatile关键字后,ChangeListener是一个忙等待的循环,他不断地从线程的Cache中获取COUNTER的值,于是,这个线程就没有时间从主内存里面同步更新后的COUNTER,就会已知卡在COUNTER=0的循环中;让循环等待
,让线程有机会把最新的数据从主内存同步到 Cache 中,于是 ChangeListener就能监听到ChangeMaker对COUNTER变量的修改。
